Simba. Unsere Text vorlesen lassen API
300ms Latenz, natürlich, $10 pro 1 Mio. Zeichen, jede gewünschte Sprache. Alles in einer API.

Teste unsere Samples – entdecke, wie unsere API Stimmen für jede Emotion steuert

Gwyneth Paltrow
Schauspielerin
Emotionssteuerung mit Tausenden voreingestellten Stimmen und jeder nachgebildeten Voice möglich
Wir entwickeln die fesselndsten KI-Stimmen – getestet mit 50M+ Nutzer:innen
Speechify bietet die weltweit meistgenutzten Text-vorlesen-lassen-Apps. Tägliches Nutzerfeedback schärft unsere KI-Stimmen und Modelle laufend.

Bestes Preis-Leistungs-Verhältnis am Markt
API-Zugang mit eingeschränkten Funktionen – ideal für kleine Projekte oder zum Testen vor einem Upgrade
- 50.000 Zeichen
- 100 Minuten Text vorlesen lassen
- 250 ms Latenz
- 50+ Sprachen
- Über 1.000 voreingestellte Stimmen
- SSML-Unterstützung
- Sprachmarkierungen
- JavaScript- und Python-SDKs
- SOC2-Zertifizierung
- Kein Voice Cloning
Unbegrenzter Zugang zu unserer API und zusätzlichen Funktionen. Keine Vertragsbindung und keine versteckten Kosten.
- Alles im Tarif „Kostenlos“ +
- Unbegrenzte Zeichen
- 2.000 Minuten Text vorlesen lassen
- Voice Cloning inklusive
- Bis zu 20× günstiger als Wettbewerber
- Skaliert auf Millionen gleichzeitiger Telefonanrufe
Individuelle API-Lösungen mit flexibler Preisgestaltung und Funktionen für Unternehmen mit besonderen Anforderungen
- Alles im Tarif „Kostenlos“ +
- Sicherheitsfragebögen
- Individuelle Bedingungen & Zusagen zu DPA/SLAs
- Maßgeschneiderte Voice Cloning & Dubbing Services
- Mehrere Benutzerkonten
- Priorisierter Support
- $5.000 jährliche Mindestabnahme
Konversations-KI
Wir haben Stimmen für Konversations-KI optimiert – z.B. Support, Vertrieb, virtuelle KI-Avatare und alle KI-Agenten.

Voiceover für Videos
Unsere Stimmen für Video, Voiceover und Dubbing erfüllen die Ansprüche von Film, YouTubern, TikTokern und Werbetreibenden.

KI-Narration
Unsere Erzählstimmen für Verlage, Autor:innen und Bildungsträger verstehen den Kontext und fesseln Zuhörer:innen bis zum Schluss.

Anpassbare Features
Mit Simba können Entwickler:innen Stimmmuster und Ton anpassen und so individuelle Hörerlebnisse für jede Anwendung schaffen.

In wenigen Minuten mit unseren Vorlagen & SDKs für JavaScript, Python & weitere Sprachen Speechify einrichten.

Wählen Sie Text-vorlesen-lassen Stimmen oder erstellen Sie eigene – maximale Auswahl und Individualisierung für Ihre Projekte.

60+ Sprachen
Stimme klonen
Zero Shot
Ein paar Sekunden Audio hochladen – sofort einen KI-Stimmenklon jeder Stimme erzeugen
Feinabgestimmte Stimme
Mehrere Sprachproben teilen & mit Speechify einen Studio-Voice-Klon im individuellen Sprechstil erzeugen

$10B+ CEO Ari Emanuel nutzt Speechify KI-Stimmenklon für alle Gewinnanrufe
Seit Feb. 2023 setzt Endeavor (NYSE: EDR) für die Eröffnung der Quartalsgespräche von CEO Ari Emanuel auf Speechify – mit seinem KI-Stimmenklon. Mit der personalisierten Stimme spart das Team wertvolle Zeit.

KI-Sprachmodell-Lösung für Unternehmen
Wir sind kein Einzellösungsanbieter. Wir sind Ihr Voice-Partner. Wir verstehen Ihren Use Case und entwickeln gemeinsam Ihre KI-Sprachlösung.
On-Premises Lösung
Wir geben unsere Stimm-Modelle für On-Prem-Deployments frei, damit Sie maximale Kontrolle & Sicherheit haben – Support inklusive.

Aussprachebibliotheken
Wir erstellen Ihre persönliche Aussprachebibliothek – jede KI-Interaktion bleibt für Ihren Anwendungsfall konsistent.

Extreme Skalierbarkeit
Wir verarbeiten Millionen paralleler Anfragen mit Unternehmensstabilität – stabil auch bei Spitzenlast.

Individuelle Stimm-Modelle
Besondere Anforderungen? Sagen Sie uns Bescheid – unser KI-Forschungsteam entwickelt passende Lösungen.
Alles andere
Seltene Sprache benötigt? Tipps zur Stimmenauswahl? Fragen Sie uns.
Die Speechify Text vorlesen lassen API (TTS API) ist ein hochwertiges Tool, das fortschrittliche Sprachsynthese, maschinelles Lernen und künstliche Intelligenz nutzt, um Text in natürlich klingende Sprache umzuwandeln – und das in einer Vielzahl von Sprachen. Zudem stehen Hunderte von Stimmoptionen zur Verfügung, einschließlich der Möglichkeit, eine eigene Stimme zu erstellen. Sie kann Transkriptions-Workflows ergänzen, indem transkribierter Text in lebensechten Ton umgewandelt wird – beispielsweise für Barrierefreiheits-Tools, E-Learning-Plattformen oder die multimediale Inhaltserstellung. Die API unterstützt Echtzeitanwendungen, sodass Entwickler lebensechte Sprachaufnahmen erstellen, die Nutzererfahrung verbessern und Workflows automatisieren können.
Ja, die Speechify Text vorlesen lassen API bietet On-Premise-Bereitstellungsoptionen für Organisationen mit speziellen Sicherheits- oder Compliance-Anforderungen. Dadurch bleibt der gesamte Text-vorlesen-lassen-Prozess in Ihrer internen Infrastruktur und sorgt für maximale Zuverlässigkeit und geringe Latenz. Kontaktieren Sie unser Team, um Ihre Anforderungen zu besprechen und maßgeschneiderte Lösungen zu finden.
Speechify Text vorlesen lassen API ist eine mehrsprachige Voice-API, die natürlich klingende Stimmen in einer Vielzahl von Sprachen anbietet. Sie verarbeitet sowohl einsprachige Texte als auch Ausgaben mit gemischten Sprachen, um das Nutzererlebnis weltweit zu optimieren. Die folgenden Sprachen werden unterstützt:
Englisch, Französisch, Deutsch, Spanisch, brasilianisches Portugiesisch, Portugiesisch, Arabisch, Dänisch, Niederländisch, Estnisch, Finnisch, Griechisch, Hebräisch, Hindi, Italienisch, Japanisch, Norwegisch, Polnisch, Russisch, Schwedisch, Türkisch, Ukrainisch, Vietnamesisch, Weißrussisch, Bengalisch, Bulgarisch, Kantonesisch, Katalanisch, Kroatisch, Tschechisch, Filipino, Georgisch, Gujarati, Ungarisch, Indonesisch, Japanisch, Koreanisch, Malaiisch, Mandarin, Marathi, Nepali, Persisch, Rumänisch, Serbisch, Slowakisch, Tamil, Telugu, Thailändisch und Urdu.
Wir arbeiten kontinuierlich daran, noch mehr Sprachoptionen hinzuzufügen.
Die Speechify TTS API ist ein leistungsstarkes Tool, das in zahlreichen Branchen eingesetzt wird. Im Bereich E-Learning wertet sie Lerninhalte mit lebensechter Erzählung auf und macht Unterricht ansprechender und barriereärmer. Für Podcasts automatisiert sie Sprachaufnahmen und sorgt für reibungslose Produktionen. Auch für Hörbücher eignet sie sich perfekt, da sie Texte in menschenähnliche Stimmen für ein immersives Hörerlebnis verwandelt. In Chatbots und konversationaler KI liefert sie hochwertige, realistische Stimmen zur Verbesserung der Nutzerinteraktion. Darüber hinaus fördert sie Inklusion für sehbehinderte Nutzer und ist ein Gamechanger für individuelle Apps mit einzigartigen Stimmen.
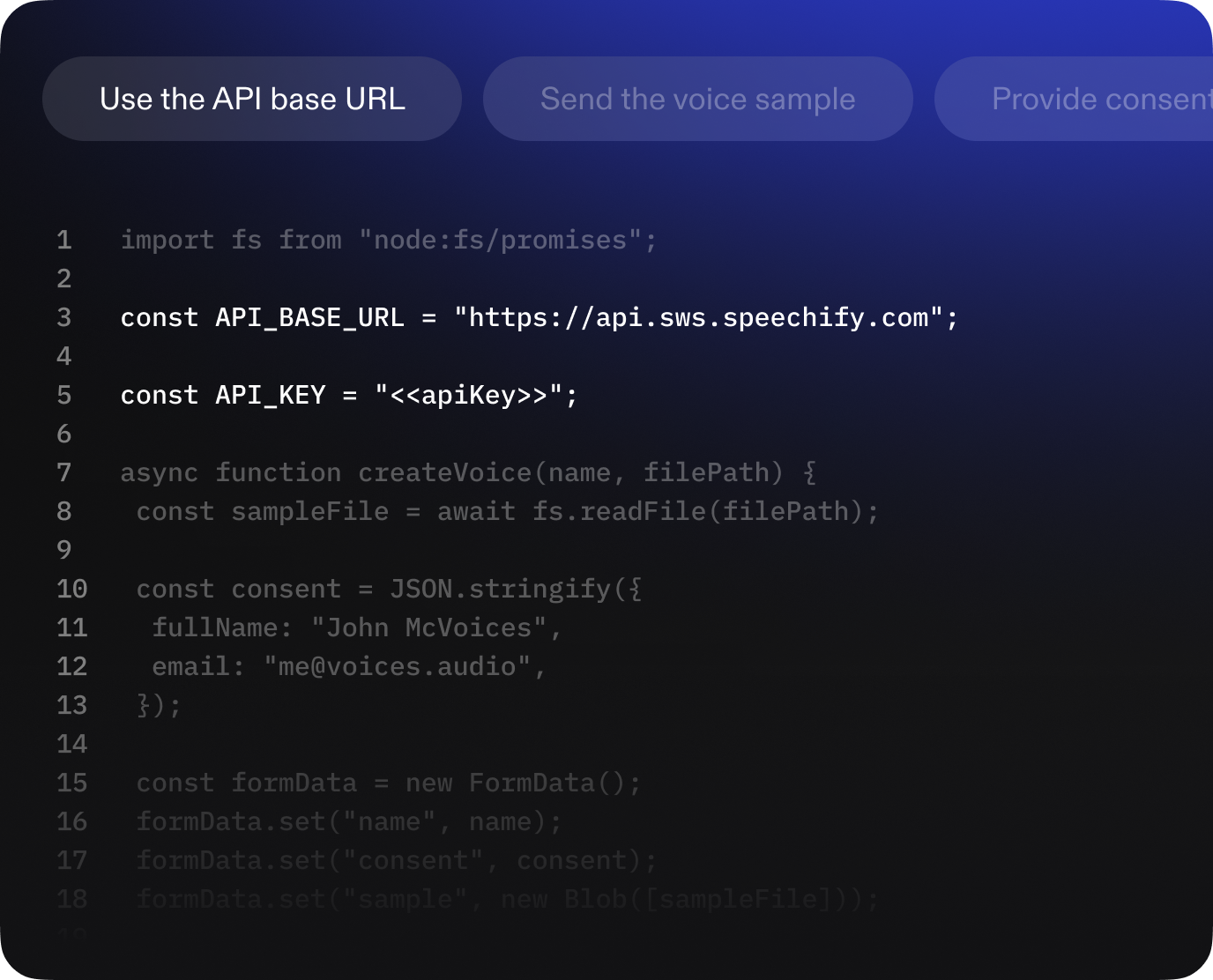
Die Integration ist unkompliziert und erfordert Grundkenntnisse in RESTful APIs. Senden Sie einfach HTTP-Anfragen mit Ihrem Texteingang im JSON-Format, konfigurieren Sie Parameter wie Stimme und Sprache und erhalten Sie die Audio-Antwort zurück. Ausführliche Integrationsleitfäden für gängige Programmiersprachen wie Python, Java und JavaScript sowie Codebeispiele finden Sie in unserer Dokumentation, um schnell loszulegen. Unsere Doku enthält Schritt-für-Schritt-Anleitungen sowie SDKs und Endpunkte für Entwickler.
Die Authentifizierung erfolgt über API-Schlüssel. Sie können Ihren Schlüssel im Dashboard Ihres Speechify-Kontos abrufen. Geben Sie den Schlüssel im Authorization-Header Ihrer HTTP-Anfragen an, um sich zu authentifizieren.
Die Speechify Text vorlesen lassen API unterstützt gängige Audio-Dateiformate wie MP3 und WAV. Das garantiert die Kompatibilität mit verschiedenen Anwendungen und Geräten, darunter Windows, Android, iOS, Mac und Chrome. Sie können das gewünschte Format in den Anfrageparametern festlegen, um die Kompatibilität mit Ihrer Anwendung sicherzustellen.
Ja, die Speechify Text vorlesen lassen API bietet eine Vielzahl von Stimmen in unterschiedlichen Sprachen und Dialekten. Sie können gezielt Stimmattribute wie Geschlecht, Akzent und Tonfall auswählen, um die Anforderungen Ihrer Anwendung zu erfüllen. Darüber hinaus unterstützt die TTS API KI-Stimmenklonen über die integrierten Spracherkennungs-Tools, sodass Sie eine eigene Stimme erstellen und für individuelle Anwendungen einsetzen können.
Die Begrenzungen hängen vom gewählten Tarif ab. Speechify Text vorlesen lassen API bietet mehrere Stufen, einschließlich eines kostenlosen Tarifs für Grundbedürfnisse und skalierbare Optionen für größere Texteingaben und Workloads. Besuchen Sie unsere Preisseite für ausführliche Informationen.
Die Preisgestaltung ist in mehrere Pläne unterteilt, je nach Nutzungsvolumen und Funktionsumfang. Detaillierte Informationen zu den einzelnen Angeboten finden Sie auf unserer Preisseite, sodass Sie die beste Option für Ihren Bedarf auswählen können. Speechify bietet ein äußerst großzügiges kostenloses Kontingent.
Datensicherheit steht an oberster Stelle. Speechify verschlüsselt alle Übertragungen und hält sich an Industriestandards, um die Privatsphäre und Sicherheit Ihrer Texteingaben und synthetisierten Sprache zu gewährleisten.
Im Vergleich zu Anbietern wie ElevenLabs, PlayHT, IBM, Microsoft Azure, Amazon Polly und Google Cloud Text-to-Speech überzeugt Speechify als beste Text-vorlesen-lassen-API durch den Fokus auf Echtzeit-Sprachsynthese, lebensechte Stimmengenerierung und herausragende SSML-Funktionalitäten. Unsere einzigartigen Stimm-Modelle bieten ein herausragendes Nutzererlebnis sowie die beste Kombination aus menschlicher Qualität, Steuerbarkeit, Enterprise-Orientierung und Skalierbarkeit am Markt.
Besuchen Sie unsere offizielle Dokumentation für ausführliche Anleitungen, Tutorials, API-Referenzen und Tipps zur Fehlerbehebung. Für weitere Hilfe steht Ihnen unser Support-Team bei allen Fragen zur Verfügung.
Ja, mit der SSML-Unterstützung der Speechify Text vorlesen lassen API können Sie die Geschwindigkeit, Tonhöhe und den Ton Ihrer synthetisierten Sprache gezielt an verschiedene Workflows oder Anwendungsfälle anpassen. Detaillierte Einstellungen finden Sie in unserer Dokumentation.
Ja, die Nutzung von durch Speechify Text vorlesen lassen Voice API generierten KI-Stimmen ist für zulässige Anwendungen legal – vorausgesetzt, Sie halten sich an unsere Nutzungsbedingungen und anwendbare Gesetze.
Ja, Sie behalten das Eigentum an den über die Speechify TTS API generierten Audiodateien und haben somit vollständige Kontrolle über deren Verwendung.
Speechify TTS API nutzt fortschrittliches maschinelles Lernen und künstliche Intelligenz, um menschenähnliche Stimmen zu erzeugen. Diese natürlich klingenden Stimmen eignen sich ideal für Hörbücher, Sprachaufnahmen und andere Anwendungen, die hochwertige Audioinhalte erfordern.
Es gibt viele API-Anbieter, darunter Google Text to Speech API und Microsoft Nuance. Die Speechify Text vorlesen lassen API bietet jedoch einige der lebensechtesten und emotionalsten KI-Stimmen auf dem Markt.
Mit Simba starten
Starten Sie mit unserer Doku, Schnellstart-Anleitung & SDKs für eine unkomplizierte Integration mit Simba.



