Kloning Suara Bahasa Inggris dengan AI: Klon Suara Anda Seketika
Buat suara kloning dengan AI Speechify dan hasilkan suara sintetis berkualitas tinggi untuk semua proyek Anda. Dari audiobook sampai pembuatan konten, Anda bisa membuat kloning AI berkualitas tinggi yang terdengar persis seperti suara asli Anda. Kloning Suara Speechify bahkan dapat digunakan langsung di browser di perangkat apa pun, termasuk Windows, Mac, iOS, atau Android. Tidak perlu instalasi software khusus.
Bagaimana Kloning Suara Bahasa Inggris Bekerja
Proses kloning suara sekarang jadi semakin mudah. Dengan teknologi suara AI Speechify Studio yang mutakhir, kloning suara Anda siap dipakai hanya dalam hitungan detik!
Langkah 1: Rekam suara Anda sendiri selama 20 detik atau unggah file audio.
Langkah 2: Algoritma canggih kami akan menganalisis ciri khas suara Anda.
Langkah 3: Gunakan fitur kloning suara untuk menghasilkan model suara personal Anda, siap digunakan di proyek apa saja.
Speechify bisa memangkas waktu membaca Anda hingga setengahnya!
Klon suara apa pun dan dengarkan dibacakan untuk Anda.
Buat akun untuk mendapatkan akses
- Hak penggunaan komersial
- Aksen, nuansa & gaya suara
- 100.000 karakter per bulan
- Kemampuan menghasilkan audio baru dalam hitungan detik
- Editor yang mudah digunakan untuk menarasikan skrip apa saja
- Platform yang dirancang untuk kreator konten, presentasi, pelatihan & e-learning, dan sebagainya.
- Integrasi mudah untuk pembuatan voice over profesional

Hemat uang, waktu, dan suara Anda dengan Kloning Suara Bahasa Inggris
Buat ribuan jam suara alami tanpa mengucapkan sepatah kata pun dengan software kloning suara ini.
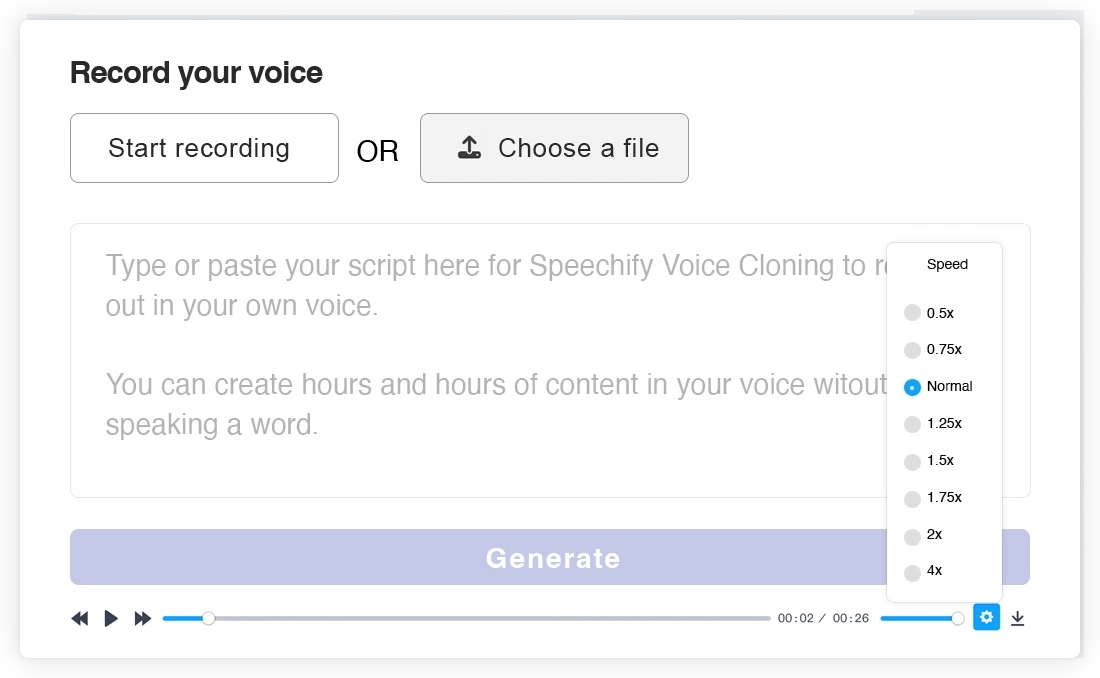
Rekam suara Anda
Rekam suara Anda langsung di browser atau unggah contoh audio. Teknologi AI voice kloning kami akan menciptakan suara unik Anda, siap digunakan di proyek, podcast, atau voice over apa saja.

Ubah Teks Jadi Suara AI Bahasa Inggris Anda dalam hitungan detik
Antarmuka Speechify Studio yang sederhana namun powerful memungkinkan Anda cukup mengetik atau menempelkan skrip. Setelah selesai, cukup satu klik untuk mengubah teks Anda menjadi suara secara otomatis dan hampir instan. Inilah alasan mengapa ini adalah alat kloning suara terbaik di pasaran. Dengarkan teks Anda dalam versi AI dari suara sendiri.

Banyak Versi
Klik 'generate' untuk mendapatkan berbagai versi pengucapan. Anda bisa dengan mudah mengubah kecepatan dan volume suara. Cukup unduh dengan satu klik dan selesai.
Dapatkan versi AI terbaik dari diri Anda sendiri dengan software kloning suara real-time Speechify.
Tambah Emosi
Tambahkan emosi dengan mudah ke suara AI Anda agar terdengar lebih manusiawi. Tambahkan penekanan, semangat, dan jeda. Anda juga bisa mengatur suara agar terdengar lebih tegas dengan kloning suara kustom.

Multi Bahasa
Dengan dukungan berbagai bahasa seperti Inggris, Jerman, Polandia, Italia, Prancis, Portugis, Hindi, dan banyak lagi, siapa pun di seluruh dunia bisa mengkloning suara mereka dan menjangkau pendengar secara global.
Beberapa Contoh Penggunaan Kloning Suara Bahasa Inggris
Gunakan kloning suara Anda dan sebarkan pesan Anda dengan lebih mudah dari sebelumnya.
Podcast & Audiobook
Buat seluruh podcast, pembacaan iklan, atau audiobook bahasa Inggris dengan suara Anda sendiri tanpa perlu membaca skrip secara manual.
Profesional
Kloning suara membawa banyak manfaat untuk profesional seperti dokter, pengacara, insinyur, ilmuwan, dan lainnya yang sering mendikte atau berbicara bahasa Inggris dalam pekerjaannya.
Pengumuman
Buat pengumuman harian perusahaan dengan mudah atau pengumuman layanan masyarakat dalam bahasa Inggris cukup dengan mengunggah skrip ke kloning suara Anda.
Momen Abadi
Klon suara orang tercinta untuk menyimpan kenangan berharga, sehingga mereka bisa menarasikan cerita favorit dengan cara yang realistis dan penuh perasaan.
Earnings Call
Permudah pengantar earnings call yang panjang dengan mengunggah skrip Anda ke kloning suara, seperti yang dilakukan Ari Emanuel dengan Speechify.
Pembuatan Konten
Hasilkan pesan pribadi, voicemail, atau konten TikTok yang menarik tanpa perlu bicara, sehingga Anda bisa membuat konten dengan efisien sambil tetap menjaga suara Anda.

Apa Itu Kloning Suara Bahasa Inggris?
Kloning suara AI Bahasa Inggris adalah teknologi maju yang memanfaatkan kecerdasan buatan, deep learning, dan speech synthesis untuk meniru karakteristik unik dari suara manusia. Proses ini melibatkan pelatihan model kloning suara menggunakan data suara asli dengan menangkap tone, pitch, dan irama. Berbeda dengan teknologi deepfake yang sering dipakai untuk menipu, kloning suara AI punya segudang kegunaan, seperti membuat narasi alami, personalisasi audiobook, dan meningkatkan alat aksesibilitas. Bahkan, Speechify memastikan model suara Anda tetap aman agar terhindar dari deepfake. Dengan perlindungan ketat, rekaman suara dan hak kekayaan intelektual Anda terjaga selama proses kloning.
Teknologi kloning suara modern kini semakin mudah digunakan, memungkinkan individu maupun bisnis memanfaatkannya tanpa butuh keahlian teknis mendalam. Dengan mereproduksi suara asli secara akurat, teknologi ini menawarkan cara-cara inovatif untuk berinteraksi dengan konten audio sekaligus mendorong batas kecerdasan buatan.
Kenapa Memilih Software Kloning Suara Bahasa Inggris Speechify?
Pemimpin AI
Speechify berada di garis depan inovasi, memberdayakan semua orang untuk meningkatkan kualitas hidup dengan kekuatan AI. Sebagai pemimpin terpercaya di industri AI, Speechify menawarkan platform terpadu yang mengintegrasikan semua kebutuhan AI Anda di satu tempat.
Mudah Digunakan
Software kloning suara AI dan rangkaian alat studio lengkap milik Speechify didesain agar mudah digunakan. Tanpa kurva pembelajaran yang rumit, bahkan pemula pun bisa membuat konten profesional hanya dalam hitungan menit.
Dukungan
Nikmati dukungan pelanggan yang tak tertandingi dari Speechify. Tim insinyur dan staf dukungan kami selalu siap menjawab pertanyaan Anda dan memastikan pengalaman yang lancar tanpa stres.
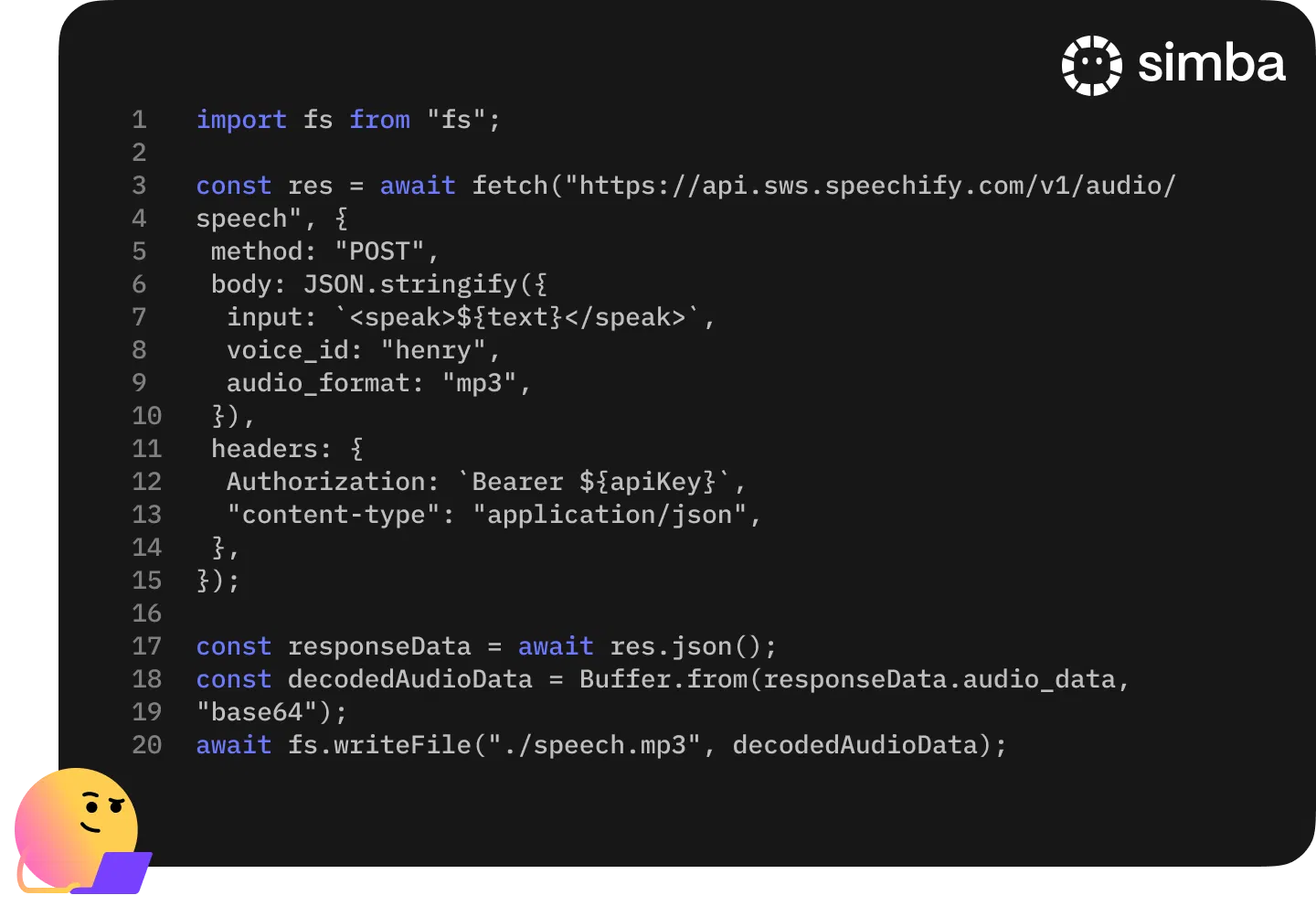
Perkenalan Text To Speech API Kami
Developer kini punya akses langsung ke suara AI Speechify yang paling alami dan digemari melalui API canggih.
Pertanyaan yang Sering Diajukan
Ya, suara bisa digandakan dengan teknologi AI. Dengan Speechify Studio Voice Cloning, Anda bisa dengan mudah meniru suara unik Anda menggunakan teknologi AI canggih, sehingga naskah dan proyek pengisi suara Anda bisa dibacakan dengan suara Anda sendiri.
Speechify AI Voice Cloning dapat meniru suara siapa pun dalam hitungan detik. AI hanya perlu mendengarkan suara Anda sekitar 30 detik. Setelah AI mengambil sampel suara seseorang, AI dapat membacakan dokumen panjang, membuat podcast, dan banyak lagi menggunakan suara yang sudah direkam sampelnya tersebut.
Punya orang tercinta yang ingin Anda tiru suaranya? Ubah teks apa pun menjadi suara mereka dengan mudah. Mau bikin podcast audio atau pengisi suara, sekarang Anda bisa membuat berjam-jam rekaman suara Anda sendiri – tanpa harus mengucapkan satu kata pun.
Speechify Studio Voice Cloning sangat cocok untuk podcast, buku audio, pemasaran, pengumuman, rapat hasil pendapatan, dan bahkan untuk menyimpan kenangan berharga. Coba sekarang. Gandakan suara Anda dalam hitungan detik!
Mulai Sekarang
Klon suara Anda dalam hitungan detik dan langsung mulai membuat konten.