Studio AI #1
Pusat Lengkap Suara & Video
Ditampilkan di
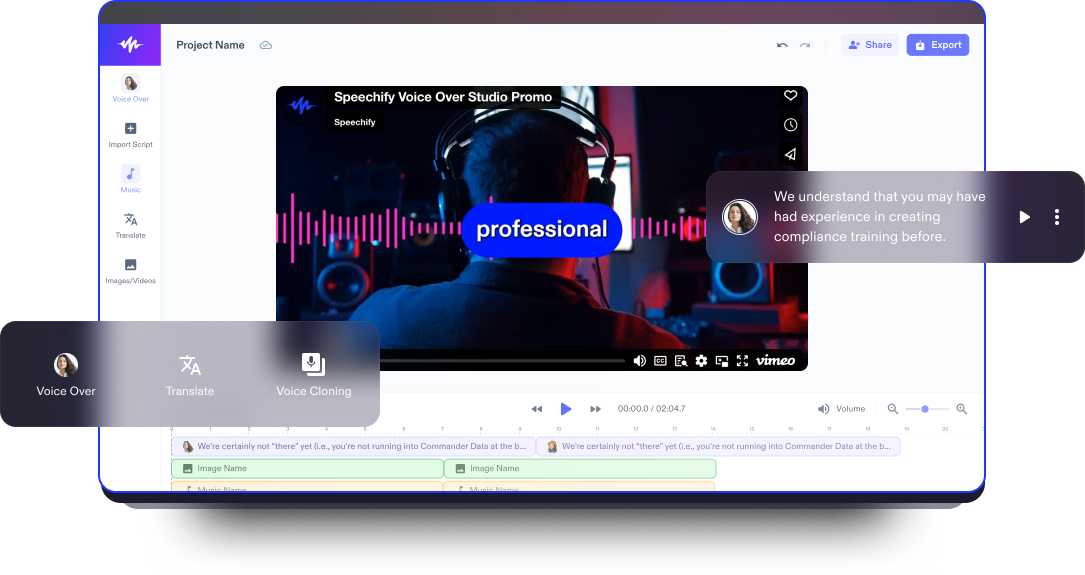
Speechify Studio: Suite AI Lengkap Pertama untuk Kreator
Untuk individu sampai tim kreatif, semuanya jadi lebih simpel.

Kloning Suara
Bikin kloning suara manusia AI berkualitas tinggi dalam hitungan detik. Tanpa instalasi, langsung di browser Anda.
Voice Over
Buat voice over se-natural suara manusia secara real time dengan AI. Narasikan teks, video, penjelasan—apa pun—dengan gaya apa saja.

Studio Video AI
Buat dan edit video dari nol dengan alat AI kami. Studio lengkap untuk editing & kreasi video Anda.

AI Dubbing
Dengan satu klik, ubah video Anda ke bahasa apa pun. Sesuaikan suara, intonasi, & kecepatan bicara.
Coba Sendiri
Sedikit contoh hal yang bisa Anda buat dengan Speechify Studio.
Buat voice over, tambah gambar, audio, video stok bebas royalti, dan kloning suara untuk proyek audio-video yang keren.
Tanpa kurva belajar, semua dari browser—kreator bisa berkarya sebebas mungkin dan wujudkan ide kreatif mereka.

Banyak pilihan suara pria & wanita dengan berbagai aksen
Setiap proyek bisa terdengar beda. Pilih ratusan suara AI & aksen, lalu sesuaikan sesuka Anda.






Speechify Studio untuk tim segala ukuran
Speechify Studio memudahkan tim kreatif, dari pekerja lepas sampai perusahaan besar.
Atur tim, bagikan aset, kolaborasi, dan luncurkan kampanye kreatif lebih cepat dari sebelumnya.
Jelajahi Lebih Banyak
Speechify API Text to Speech
Kami senang menghadirkan API text-to-speech dengan suara AI Speechify yang paling natural & favorit langsung untuk developer di seluruh dunia.