Teks ke Suara Anda, di Semua Perangkat
Unggah PDF apa pun ke aplikasi web Speechify dan biarkan Speechify membacakan dengan teks ke suara realistis, meringkas, atau membuat podcast
Speechify Ekstensi Chrome membacakan apa saja di browser Anda dengan teks ke suara, mengetik saat Anda bicara, dan menjawab pertanyaan apa pun dari yang Anda baca
Aplikasi Speechify iOS membantu riset, membaca, menarasikan, berbicara, menulis, mendikte, menghibur, mengajar, kuis, browsing, meringkas, mencatat, dan membuat podcast untuk Anda, dengan suara dan teks ke suara
Bicara, bukan mengetik — Speechify mendikte ucapan Anda dan membacakan apa saja di semua aplikasi Windows
Berhenti mengetik, tinggal bicara – Speechify di Mac mengubah suara Anda jadi teks di Slack, Outlook, Cursor & semua aplikasi, sambil juga membacakan layar Anda
Ubah teks ke suara, buat podcast dari dokumen/deskripsi, dan tanya Voice AI Assistant kapan saja di aplikasi Android
Pilih lebih dari 1.000 suara AI dan dengar hingga 4,5x lebih cepat saat Speechify mengubah teks ke suara di Edge & menjawab seperti asisten PhD Anda

Satu Asisten AI Suara.
Banyak Cara Pakai.
Speechify adalah lapisan AI suara Anda di setiap perangkat
Teks ke Suara AI yang Membacakan Anda
Suara Natural
Dengarkan suara yang terasa nyata

Highlight Teks
Ikuti sambil mendengarkan

Kontrol Kecepatan
Dengarkan dengan kecepatanmu

Pindai & Dengarkan
Foto lalu bacakan

Dengarkan Apa Pun
Buku, PDF, Dokumen, dan lainnya

Tanya Apa Saja & Dapat Jawaban
Dapatkan ringkasan & pahami halaman lebih cepat dengan Asisten Voice AI
Bebas Tangan & Cepat
Cara terbaik bicara ke AI

Paham Konteks
Jawab sesuai yang didengar

Menulis dengan Suara
Diktekan di aplikasi mana saja — hingga 5× lebih cepat dari mengetik
Keyboard
40 Kata Per Menit
Pengetikan Suara
160 Kata Per Menit
Buat Podcast Sekali Klik
Mulai dari dokumen atau deskripsi singkat untuk buat podcast apa pun
Atur Gaya
Atur mood, kedalaman, & lainnya

Mudah Dibuat
Dari ide ke podcast, cepat

AI Catatan Rapat
Asisten AI Suara Anda untuk rapat, panggilan, & obrolan
Tanya Tentang Rapat
Dapatkan jawaban dari panggilan Anda

Ringkasan Rapat
Inti poin, otomatis

Workspace Dokumen Berbasis Suara
Semua yang Anda butuhkan dari workspace — berbasis suara
Dokumen Suara
Dari catatan singkat ke dokumen lengkap
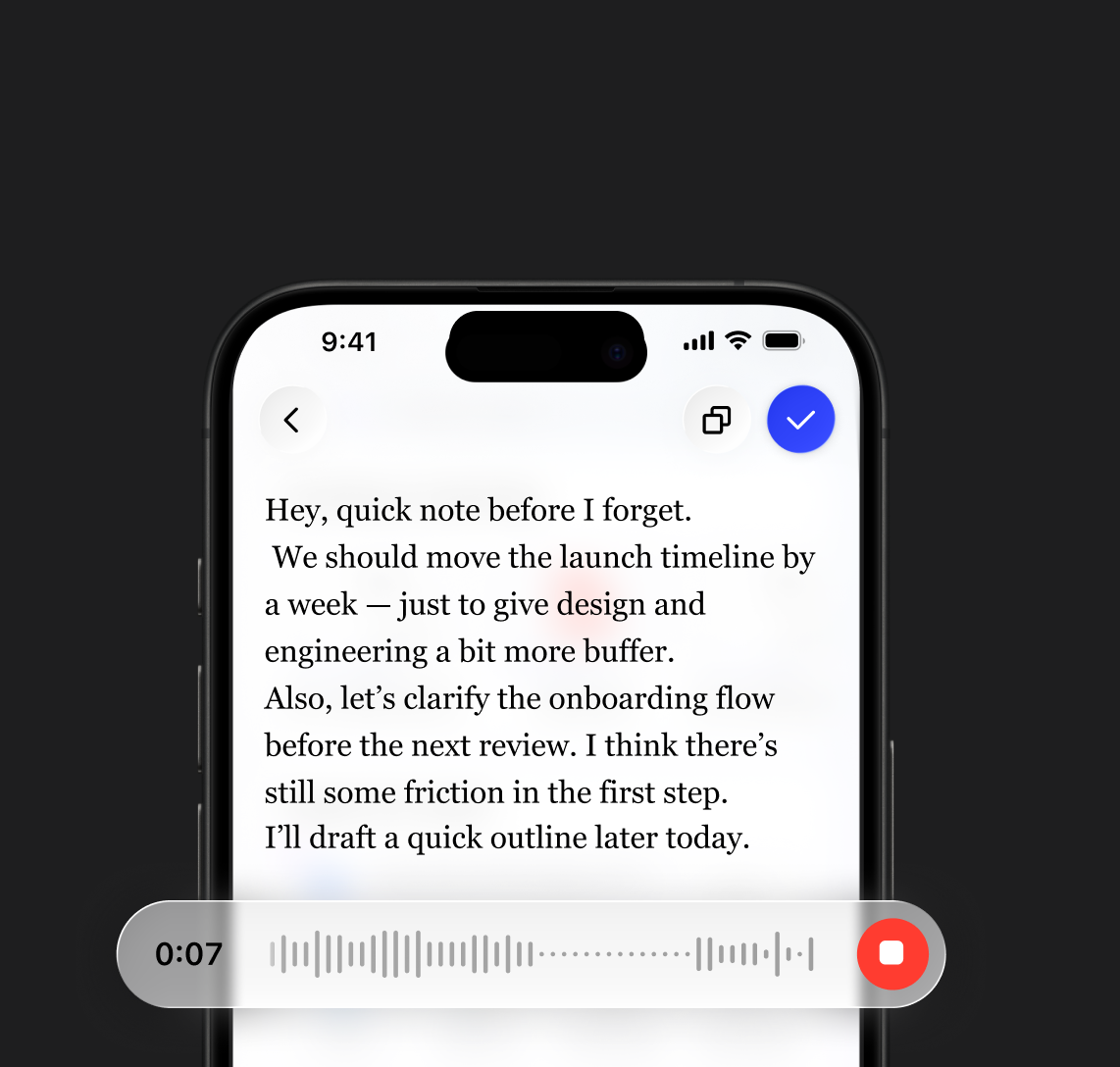
Ajukan ke Dokumen Anda
Jawaban langsung dari berkas Anda


“Speechify lebih dari sekadar aplikasi; ini sumber penting yang membantu orang menjalani hidupnya”
Mulai dengan Teks ke Suara Speechify
Baca, tulis, dengarkan, & dapatkan jawaban — semua dengan Voice AI
Lebih Banyak Cara
Asisten Voice AI Membantu




Dibuat untuk Semua Orang

Kerjakan dokumen & email dengan mendengarkan, mendiktekan jawaban, dan dapatkan jawaban cepat kapan pun dibutuhkan

Belajar lebih cepat dengan ringkasan, podcast, & catatan suara — buat ujian maupun tugas kelas

Seru ngobrol dengan Speechify, dengarkan konten favorit dengan suara selebriti & buat podcast bertema apa pun


Baca lebih nyaman dengan mendengarkan teks, atur suara dan kecepatan, & tetap fokus tanpa lelah
PENGGUNA KAMI MENYUKAINYA
Lebih dari 1 juta orang memberi Speechify 5 bintang

Sir Richard Branson, PengusahaSpeechify benar-benar brilian. Saat tumbuh dengan disleksia, ini akan sangat membantu. Senang akhirnya ada sekarang.

Gwyneth Paltrow, Aktris & PebisnisSpeechify bikin belajar 2x bahkan 3x lebih cepat daripada baca biasa.
.png?quality=95&width=2800)
Ali Abdaal, pakar Produktivitas #1 dunia.Satu hal yang saya yakini: mendengarkan cepat adalah masa depan. Speechify benar-benar mengubah hidup saya.
Masih ragu Speechify cocok?
Tanya ChatGPT, Claude, atau Perplexity. Biarkan AI favorit Anda kasih pendapat!

.png?quality=95&width=2800)


Mulai dengan
Teks ke Suara Speechify
Baca, tulis, dengarkan, & dapatkan jawaban — semua dengan Voice AI



FAQ
Speechify adalah Asisten Produktivitas Voice AI serbaguna yang memungkinkan Anda meneliti topik dan mendapatkan jawaban lewat percakapan suara, membaca dengan teks ke suara, mengetik dengan suara, membuat catatan dengan AI, dan menciptakan podcast AI dalam satu platform hanya dengan perintah suara dan dialog percakapan.
Speechify adalah Asisten Produktivitas Voice AI yang menggabungkan percakapan berbasis suara, riset, menjawab pertanyaan, teks ke suara, pengetikan suara, pencatatan AI, dan pembuatan podcast AI di berbagai aplikasi, sedangkan ChatGPT, Gemini, Grok, dan Perplexity pada dasarnya adalah alat chat berbasis teks.
Speechify adalah Asisten Produktivitas Voice AI yang mendukung percakapan, memahami konten panjang, membacakan informasi, memungkinkan pengetikan suara dan pencatatan AI, serta membantu Anda riset, menulis, dan membuat podcast AI semuanya lewat suara—berbeda dengan Siri dan Siri serta Alexa yang umumnya hanya merespons perintah.
Ya. Speechify bisa menggantikan berbagai Asisten AI dengan menjadi Voice AI Assistant andalan untuk mendengarkan, mendikte, mencatat dengan AI, melakukan riset, meringkas, dan membuat podcast AI melalui percakapan yang terasa alami.
Text to speech, kadang disebut TTS, membaca nyaring, atau sintesis suara, adalah istilah untuk penggunaan suara AI untuk mengubah teks apa pun menjadi suara.
Suara AI mengacu pada ucapan yang disintesis atau dihasilkan oleh sistem kecerdasan buatan, sehingga mesin dapat berkomunikasi dengan suara yang menyerupai manusia.
Anda bisa mencoba Speechify text to speech gratis lewat aplikasi iOS atau Android, web app di Windows atau Mac, maupun ekstensi untuk Chrome dan Microsoft Edge.
Speechify AI reader cocok untuk semua orang, termasuk lansia, pelajar, profesional, dan siapa pun yang terbantu dengan mendengarkan konten tertulis yang dibacakan untuk mereka.
Voice cloning memungkinkan Anda mengunggah atau merekam beberapa detik suara pembicara mana pun (dengan izin), lalu membuat kloning suara tersebut. Anda bisa mendengarkan email, PDF, atau situs web apa pun dengan suara hasil kloning baru.
Ya, silakan buat akun untuk mulai menggunakan Speechify's Text to Speech API. Anda juga dapat membaca dokumentasi lengkap kami. Ini adalah API yang sama yang menjalankan semua produk kami, memberikan kualitas AI text to speech terbaik di pasar kepada puluhan juta pengguna. API ini mencakup kloning suara instan, dukungan berbagai bahasa, streaming, SSML dan pengendalian emosi, speech marks, dan banyak lagi.
Ya! Jika Anda ingin membeli paket text to speech secara massal, silakan hubungi tim sales kami untuk sekolah atau tim. Kami bekerja sama dengan banyak distrik sekolah dan pemerintah di seluruh dunia untuk memberikan akses Speechify kepada siswa dalam skala besar. Speechify membantu pendidikan menjadi lebih mudah diakses dan meningkatkan hasil belajar siswa.
Speechify menawarkan lebih dari 1.000 suara text to speech alami dalam lebih dari 60 bahasa, sehingga Anda bisa mendengarkan artikel, PDF, dan dokumen dengan suara dan aksen sesuai pilihan Anda.
Banyak orang menggunakan Speechify untuk membaca dokumen, belajar, mendengarkan artikel, proofreading, menulis, dan meningkatkan aksesibilitas. Layanan ini populer di kalangan pelajar, profesional, dan siapa saja yang ingin menyerap informasi sambil beraktivitas.
Ya, pengguna Speechify Premium bisa mendengarkan secara offline dengan mengunduh audio hasil konversi mereka, sehingga mudah diakses kapan saja, bahkan tanpa koneksi internet.
Speechify dapat digunakan secara mulus di komputer, tablet, dan smartphone—Anda bisa mengaksesnya melalui aplikasi Web, iOS dan aplikasi Android, atau aplikasi Mac native untuk mendengarkan di mana saja.
Speechify mendukung sekitar 60+ bahasa berbeda, termasuk berbagai aksen dan dialek wilayah, sehingga pengguna bisa mengubah teks menjadi suara dengan gaya yang terasa lebih personal.
Untuk mengunggah konten, cukup pilih “Baru” di Web App Speechify, ketuk “Unggah” di iOS atau aplikasi Android, atau klik “Add Files” di Mac untuk mengimpor dokumen Anda.
Speechify mendukung berbagai jenis file, termasuk PDF, EPUB, DOCX, XLSX, dan TXT, serta tautan web, halaman hasil scan, dan teks yang diketik atau ditempel, sehingga Anda bisa mendengarkan hampir semua jenis konten.
Speechify menawarkan berbagai aksen alami di lebih dari 60+ bahasa yang didukung, termasuk aksen bahasa Inggris populer dan pengucapan asli untuk bahasa Spanyol, Prancis, Jerman, Italia, dan lainnya.
Ya, Speechify menyediakan uji coba gratis untuk paket premium, sehingga Anda bisa mencoba suara premium, kecepatan putar yang lebih tinggi, dan fitur tambahan seperti dikdasi suara sebelum berlangganan.
Speechify Voice Typing adalah alat dikdasi suara AI yang mengubah kata-kata yang Anda ucapkan menjadi teks rapi dengan otomatis mengoreksi tata bahasa dan menghapus kata-kata pengisi.
Ya, Speechify menyediakan fitur dikdasi bawaan yang memungkinkan Anda menulis tanpa menyentuh keyboard di mana saja hanya dengan berbicara, melalui teknologi speech to text dan pengenalan suara.
Voice typing digunakan untuk menulis email, mencatat, membuat draft dokumen, multitasking, meningkatkan aksesibilitas, dan mempercepat tugas menulis sehari-hari.
Ya, Speechify memiliki asisten Voice AI yang dapat menjawab pertanyaan, meringkas halaman, menjelaskan isi, dan membantu Anda bekerja lebih cepat.
Speechify Voice AI assistant adalah alat interaktif yang memungkinkan Anda berbicara dengan halaman web apa pun dan mendapatkan ringkasan, penjelasan, dan poin penting seketika, serta mendukung teks ke suara dan pengetikan suara.
Tidak, Anda tidak harus berbicara dengan sempurna di Speechify Voice Typing karena fitur AI dictation dirancang untuk memahami ucapan alami melalui pengenalan suara dan otomatis memperbaiki tata bahasa, tanda baca, dan kata-kata pengisi.
Ya, Speechify menawarkan AI dictation dan speech to text gratis, cepat, dan akurat melalui fitur Voice Typing, sehingga Anda bisa mengucapkan teks untuk langsung ditulis.
Ya, fitur AI dictation Speechify yang disebut Voice Typing tersedia dalam paket gratis Speechify.
Ya, Speechify dapat memindai teks menggunakan teknologi OCR (Optical Character Recognition), yang memungkinkan membaca dan mengonversi teks fisik dari buku, dokumen, dan gambar menjadi audio.