BEST AI DUBBING FOR VIDEO
VIDEO AI DUBBING
Esiletõstetud
Mis on AI-dubleerimine?
AI-dubleerimine kasutab tipptasemel tehisintellekti, et tõlkida ja sättida videod eri keeltesse. Erinevalt tavapärasest dubleerimisest, kus kasutatakse inimtõlkeid ja näitlejaid, teeb AI seda automaatselt ja sünteesib uued hääled.
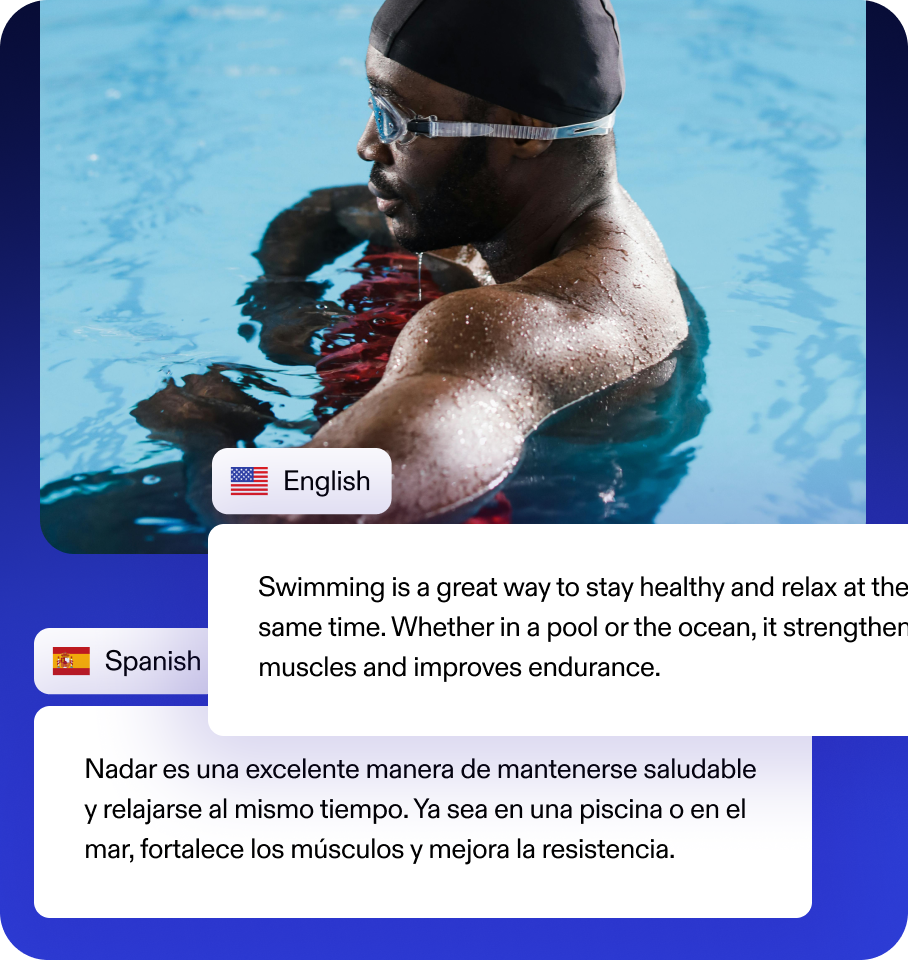
Parim AI-dubleerimine video ja sisu lokaliseerimiseks
Ületa keelebarjäärid Speechify AI dubleerijaga, mis paneb sinu video kõnelema kümnetes keeltes. Jõua ülemaailmse vaatajaskonnani kiiresti, muutes oma originaalheli lokaliseeritud sisuks.
Dubleeri sisu enam kui 60 keeles

Jõua üleilmselt vaatajateni
Dubleeri oma videoid hetkega mitmesse keelde AI abil, ilma kallite seadmeteta. Tee sisu kättesaadavaks hispaania, prantsuse, itaalia, portugali, saksa, hiina, jaapani jm keeltes.
Õppimiskõver puudub
Dubleeri videoid lihtsalt Speechify Studio abil – lae skript üles, vali elutruu AI hääl ja keel ning saad kohe tõlgitud sisu.

Inimkõlalised hääled
Speechify Studio dubleerib sinu video enam kui 60 keelde ja aktsenti loomulike häältega, mis meenutavad pärisinimesi. Tippkvaliteediga dubleerimine säilitab emotsiooni ja tempo nagu algses audios.
AI-videotõlke kasutusvõimalused
AI-dubleerimise võimalused on peaaegu piiramatud – siin on vaid mõned näited.

Sisuloomine
Õpeta maailma mitmekeelse dokumentaaliga teleris või sotsiaalmeedias. Lase AI-l dubleerida sinu filmid, YouTube'i videod jpm eri keeltesse ja jõua globaalse publikuni.

Koolitusvideod
Loo ja dubleeri sadu koolitusvideoid nüüd kiiresti. Toota õpetusvideosid töötajatele või jõua õpetajana oma õpilasteni sama vaevata.

Turundusvideod
Kasva ülemaailmseks ilma uusi videoid tegemata. Dubleeri olemasolev videokogu ja suurenda oma kontakte ning müüki.
Dubleeri AI-häälega kloonimise abil
Speechify Studio AI häälkloon võimaldab luua isikliku hääle vaid 20-sekundilise salvestuse põhjal sinust või lähedasest. See mitte ainult ei muuda heli isikupärasemaks, vaid lubab kiiresti toota suurel hulgal kohandatud sisu tuttava häälega.

Tutvustame oma teksti kõneks API-t
Jagame AI-hääle API-t, mis annab Speechify loomulikud ja hinnatud AI-hääled arendajatele.
Õpi AI-videotõlke kohta
Oled sa algaja või kogenud kasutaja, loe parimaid artikleid dubleerimisest.
KKK
Tehisintellekti dubleerimine tähendab protsessi, kus tehisintellekti abil luuakse videotele erinevates keeltes häälpealelugemised, selle asemel et kasutada traditsioonilisi näitlejaid.
Speechify Dubbing on parim valik. Speechify abil saab igaüks veebis tasuta dubleerida. Vali lihtsalt AI-hääl ja keel ning kuula, kuidas sinu tekst loetakse valjusti ette uues keeles.
Traditsioonilise hääl-dubleerimise või tõlkele suunatud sisu puhul vahetavad näitlejad algse helirea manuaalselt uute, teises keeles salvestatud võtete vastu. Tehisintellekti dubleerimise puhul, näiteks Speechify Studio's, on protsess automatiseeritud. Tehisintellekt transkribeerib algse dialoogi, tõlgib selle teise keelde ja kasutab tekst-kõneks algoritme uue helirea loomiseks.
Dubleerimise näiteks on ingliskeelse filmi muutmine nii, et ingliskeelne dialoog asendatakse hindikeelsega, kasutades tehisintellekti hääli. Selleks transkribeeritakse esmalt ingliskeelne dialoog, tõlgitakse see hindi keelde ning seejärel kasutatakse tekst-kõneks tehnoloogiat, et genereerida uus hindikeelne dialoog, mida valjusti ette loetakse elutruude AI-häältega.
VO ehk häälpealelugemine tähendab jutustuse lisamist videole, et kommenteerida või selgitada toimuvat. Dubleerimine tähendab aga algse dialoogi asendamist teise keele dialoogiga. Mõlemaid protsesse saab tehisintellekti tehnoloogiate, näiteks Speechify Studio abil, oluliselt kiirendada ja odavamaks muuta, pakkudes tõhusamat ja kulusäästlikumat lokaliseerimisstrateegiat.
Tehisintellektiga dubleerimiseks pead kasutama AI-dubleerimisteenust nagu Speechify Studio. Tavaliselt tuleb sul oma video üles laadida. Seejärel transkribeerib AI algse dialoogi, tõlgib selle soovitud keelde ja kasutab tekst-kõneks tehnoloogiat, et valjusti ette lugeda skriptid ning luua uus helirida.
Tehisintellekti dubleerimisel on mitu eelist. See parandab videote ligipääsetavust, võimaldades sisu pakkuda suuremale ja keeleliselt mitmekesisemale publikule. Samuti on see soodsam ja ajasäästlikum kui traditsioonilised lahendused, kus tuleb näitlejatega eraldi kokku leppida ja salvestusi korraldada. Kvaliteetne AI-dubleerimine võib vaatamiskogemust oluliselt parandada, pakkudes reaalajas dubleeritud sisu ilma subtiitriteta, ning on eriti kasulik sisuloojatele, e-õppe platvormidele ja sotsiaalmeedias.
Dubleerimine on filminduse ja teletootmise protsess, kus võtetel salvestatud algsed heliread asendatakse mõnes muus keeles salvestatud helidega.
Filmides tähendab dubleerimine algse dialoogi asendamist teise keelde tõlgitud dialoogiga. See võimaldab filmist aru saada ja seda nautida ka neil, kes algset keelt ei räägi. Dubleeritud hääled püütakse üldjuhul sünkroonida näitlejate huulte liikumisega, et säilitada loomulikkus ja usutavus.
Teleseriaalides tähendab dubleerimine algse dialoogi asendamist tõlgitud dialoogiga mõnes teises keeles. See aitab saatel jõuda laiema, eri keeli kõneleva publikuni. Protsessis sünkroonitakse dubleeritud hääled näitlejate suu liikumiste ja miimikaga, et tagada sujuv ja loomulik vaatamiskogemus.