BEST AI DUBBING FOR VIDEO
VIDEO AI DUBBING
แนะนำใน
AI Dubbing คืออะไร?
AI dubbing ใช้เทคโนโลยีอัจฉริยะขั้นสูงช่วยแปลและพากย์เสียงวิดีโอเป็นภาษาต่าง ๆ แทนการพากย์แบบเดิมที่ใช้คนล้วน ๆ AI จะแปลพร้อมสร้างเสียงอัตโนมัติให้คุณ
สุดยอด AI Dubbing เพื่อการแปลวิดีโอและเนื้อหา
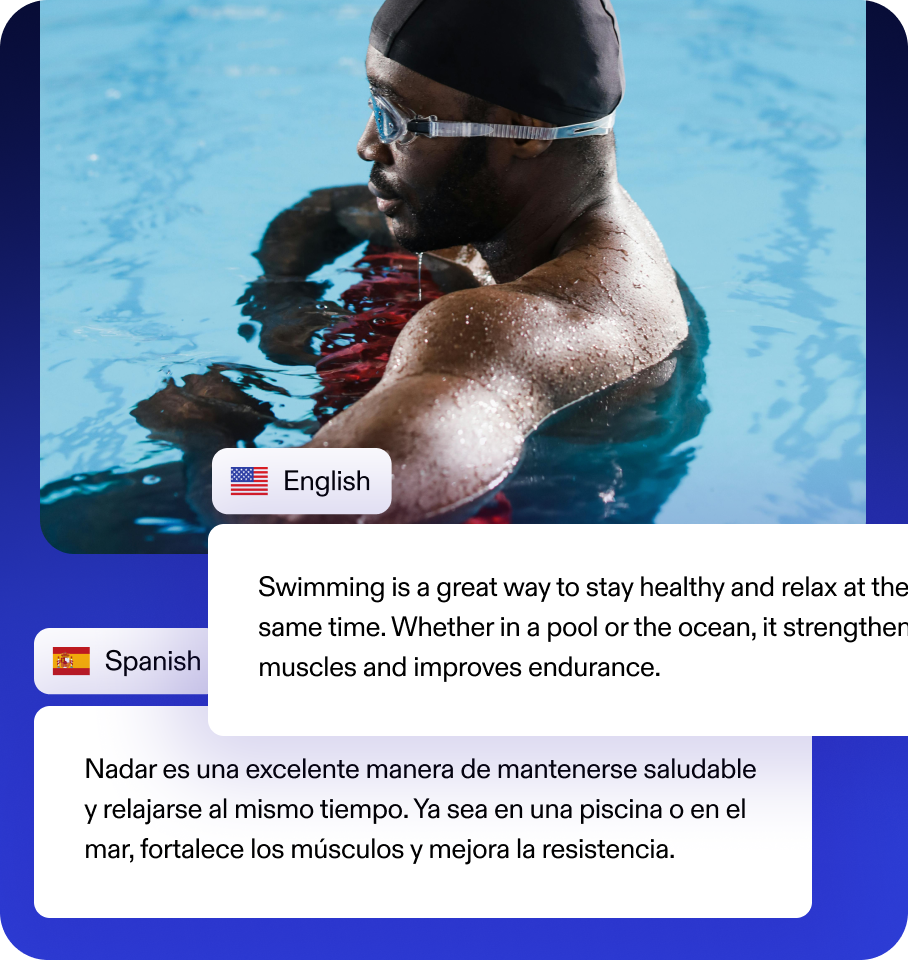
ลบกำแพงภาษาออกไปด้วยเครื่องมือพากย์เสียง AI ของ Speechify พากย์เสียงได้หลายภาษา เชื่อมต่อผู้ชมทั่วโลกด้วยการเปลี่ยนเสียงต้นฉบับให้เป็นเวอร์ชันท้องถิ่นได้ง่าย ๆ
พากย์เนื้อหาได้มากกว่า 60 ภาษา

ขยายสู่ผู้ชมทั่วโลก
พากย์วิดีโอเป็นหลายภาษาได้ทันใจด้วย AI ไม่ต้องใช้อุปกรณ์แพง ให้คอนเทนต์คุณเข้าถึงผู้ใช้ที่พูดสเปน ฝรั่งเศส อิตาลี โปรตุเกส เยอรมัน จีน ญี่ปุ่น ฯลฯ
ใช้งานง่าย ไม่ต้องเรียนรู้ใหม่
พากย์วิดีโอง่าย ๆ ด้วย Speechify Studio แค่อัปโหลดสคริปต์ เลือกเสียง AI เสมือนจริงและภาษา ระบบจะช่วยแปลให้ทันที

เสียงเหมือนมนุษย์
Speechify Studio พากย์วิดีโอของคุณได้มากกว่า 60 ภาษา ด้วยเสียงและสำเนียงใกล้เคียงมนุษย์ ถ่ายทอดอารมณ์และจังหวะได้เหมือนเสียงต้นฉบับ
การใช้งาน AI Video Dubbing
AI dubbing นำไปใช้ได้หลากหลาย ต่อไปนี้คือตัวอย่างบางส่วน

สร้างคอนเทนต์
เผยแพร่ความรู้ผ่านสารคดีหลายภาษาบนทีวีหรือโซเชียล ให้ AI พากย์หนัง วิดีโอ YouTube ฯลฯ เป็นหลายภาษา เข้าถึงผู้ชมทั่วโลก

วิดีโออบรม
ผลิตวิดีโอฝึกอบรมหรือคอร์สมากแค่ไหนก็พากย์เสียงได้ทั้งหมด สร้างวิดีโอสอนสำหรับพนักงานหรือผู้เรียนได้แบบสบาย ๆ

วิดีโอโฆษณา
ขยายตลาดสู่ระดับสากลโดยไม่ต้องถ่ายทำใหม่ พากย์คลังวิดีโอที่มีอยู่แล้วและเพิ่มยอดผู้ติดตาม
พากย์ด้วย AI Voice Cloning
เทคโนโลยีโคลนเสียง AI ของ Speechify Studio ให้คุณสร้างเสียงเฉพาะบุคคลจากตัวอย่างเสียงจริงแค่ 20 วินาที ทั้งเพิ่มความเป็นส่วนตัวและผลิตเสียงจำนวนมากได้รวดเร็ว ใช้เสียงคุ้นหูอ่านข้อความ ทำคอนเทนต์จำนวนมากได้อย่างมีประสิทธิภาพ

แนะนำ Text To Speech API
เรามี AI Voice API ให้คุณเชื่อมต่อเสียง AI ของ Speechify ได้โดยตรงสำหรับนักพัฒนา
เรียนรู้เกี่ยวกับ AI Video Dubbing
ไม่ว่าคุณจะเพิ่งเริ่มหรือมีประสบการณ์ อ่านบทความด้านการพากย์เสียงที่คัดมาให้แล้ว
คำถามที่พบบ่อย
การพากย์ด้วย AI คือการใช้ปัญญาประดิษฐ์สร้างเสียงบรรยายให้วิดีโอได้หลายภาษา แทนการใช้ผู้พากย์เสียงมนุษย์แบบเดิม
Speechify Dubbing คือทางเลือกที่ดีที่สุด ด้วย Speechify ใคร ๆ ก็พากย์ออนไลน์ได้ฟรี เพียงเลือกเสียง AI และภาษา แล้วให้สคริปต์ของคุณ อ่านออกเสียง ในภาษาใหม่
การพากย์แบบดั้งเดิมหรือการทำเวอร์ชันแปล ต้องใช้นักพากย์มาบันทึกเสียงใหม่แทนเสียงต้นฉบับทีละภาษา ส่วนการพากย์ด้วย AI อย่าง Speechify Studio กระบวนการจะเป็นแบบอัตโนมัติ โดย AI จะถอดความบทสนทนาต้นฉบับ แปลเป็นภาษาปลายทาง และใช้อัลกอริทึมแปลงข้อความเป็นเสียงเพื่อสร้างแทร็กเสียงใหม่
ตัวอย่างของการพากย์ เช่น นำภาพยนตร์ภาษาอังกฤษมาแทนบทสนทนาเป็นภาษาฮินดีด้วยเสียง AI ขั้นตอนคือถอดความบทสนทนาอังกฤษต้นฉบับ แปลเป็นภาษาฮินดี แล้วใช้เทคโนโลยีแปลงข้อความเป็นเสียงเพื่อสร้างบทสนทนาฮินดีใหม่ ซึ่งจะ อ่านออกเสียง ด้วยเสียง AI ที่สมจริง
VO หรือ voice over คือการเติมเสียงบรรยายให้กับวิดีโอ มักใช้เพื่อคอมเมนต์หรืออธิบายสิ่งที่เกิดขึ้น ส่วน dubbing คือการแทนบทสนทนาต้นฉบับในวิดีโอด้วยบทสนทนาภาษาต่างประเทศ กระบวนการทั้งสองสามารถยกระดับได้ด้วยเทคโนโลยี AI อย่าง Speechify Studio ทำให้การทำโลคัลไลเซชันรวดเร็วและคุ้มค่าขึ้น
ในการพากย์ด้วย AI คุณต้องใช้บริการพากย์ด้วย AI เช่น Speechify Studio โดยทั่วไปคุณเพียงอัปโหลดวิดีโอของคุณ จากนั้น AI จะถอดความบทสนทนาต้นฉบับ แปลเป็นภาษาที่ต้องการ และใช้เทคโนโลยีแปลงข้อความเป็นเสียงเพื่อ อ่านออกเสียง สคริปต์และสร้างแทร็กเสียงใหม่
การพากย์ด้วย AI มีข้อดีหลายด้าน ช่วยเปิดทางให้ผู้ชมต่างภาษาเข้าถึงเนื้อหาวิดีโอได้มากขึ้น ประหยัดทั้งงบและเวลาเมื่อเทียบกับวิธีการพากย์แบบดั้งเดิมที่ต้องประสานงานกับนักพากย์ เสียงพากย์ AI คุณภาพสูงยังช่วยยกระดับประสบการณ์รับชม ด้วยการพากย์แบบเรียลไทม์โดยไม่ต้องพึ่งคำบรรยาย เหมาะมากสำหรับครีเอเตอร์ แพลตฟอร์มการเรียนรู้ออนไลน์ และโซเชียลมีเดีย
การพากย์คือกระบวนการในงานภาพยนตร์และการผลิตโทรทัศน์ ที่แทนแทร็กเสียงซึ่งบันทึกขณะถ่ายทำ ด้วยเสียงที่บันทึกใหม่เป็นอีกภาษา
ในภาพยนตร์ การพากย์หมายถึงการแทนที่บทสนทนาต้นฉบับด้วยบทสนทนาที่แปลเป็นภาษาต่างประเทศ ช่วยให้ผู้ชมที่ไม่พูดภาษาต้นฉบับเข้าใจและสนุกกับภาพยนตร์ได้ โดยเสียงพากย์มักต้องซิงก์ให้เข้ากับการขยับปากของนักแสดงเพื่อรักษาความต่อเนื่องและความสมจริง
การพากย์ในรายการทีวีคือการแทนที่บทสนทนาต้นฉบับด้วยบทสนทนาที่แปลเป็นอีกภาษา ทำให้รายการเข้าถึงผู้ชมหลากหลายภาษาได้มากขึ้น กระบวนการนี้รวมถึงการซิงก์เสียงพากย์ให้เข้ากับการขยับปากและอารมณ์บนใบหน้า เพื่อให้การรับชมลื่นไหล