BEST AI DUBBING FOR VIDEO
VIDEO AI DUBBING
Featured In
What is AI Dubbing?
AI dubbing utilizes advanced AI technology to translate and voice video content into different languages. Unlike traditional dubbing, which relies heavily on human translators and voice actors, AI dubbing automates video translation and voice synthesis.
Best AI Dubbing for Video and Content Localization
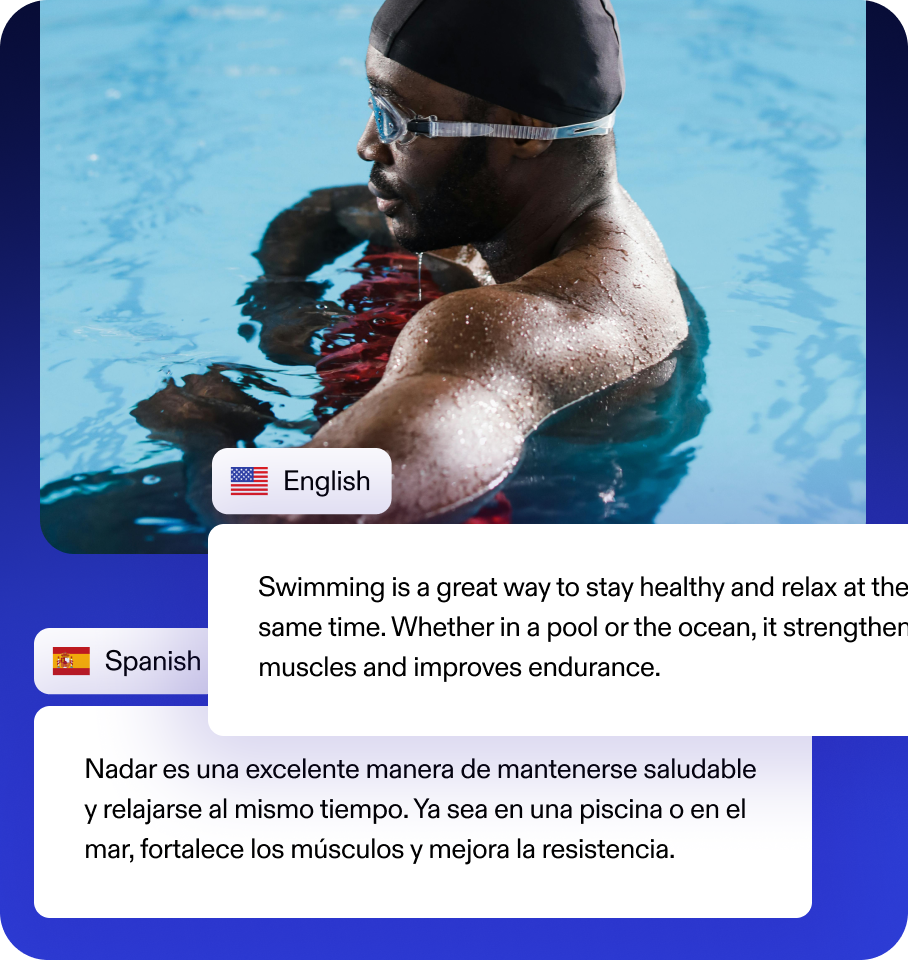
Break down language barriers with Speechify's AI dubbing tool, offering dubbing in various languages. Connect with global audiences effortlessly by transforming your original audio into localized content.
Dub Content in 60+ Languages

Reach a Global Audience
Dub your videos into multiple languages instantly with AI, no expensive equipment needed. Make your content accessible in Spanish, French, Italian, Portuguese, German, Chinese, Japanese, and more.
Zero Learning Curve
Easily dub videos with Speechify Studio. Upload your script, select a lifelike AI voice, choose a language, and enjoy instant translations.

Humanlike Voices
Speechify Studio can dub your video into 60+ languages and accents that are indistinguishable from human speech. The high-quality dubbing captures the same emotion and pacing as the original audio.
AI Video Dubbing Use Cases
The applications for AI dubbing are limitless, but here are just a few.

Content Creation
Educate the world with a multilingual documentary via television or social media. Sit back and let AI dub your movies, YouTube videos, and more into multiple languages and reach a worldwide audience.

Training Videos
If you create 100s of course or training videos you can now dub all of them. Create tutorial videos for employees or reach students as an educator easily.

Marketing Videos
Grow into the global market without creating unique videos. Dub your existing video library and scale your leads and acquisition.
Dub with AI Voice Cloning
Speechify Studio's AI voice cloning technology allows users to create a custom voice from just a 20-second recording of themselves or their loved ones. This feature not only enhances personalized audio experiences but also enables the creation of content at scale, allowing any text to be read back in a familiar voice, making it highly efficient for producing large volumes of customized audio content.

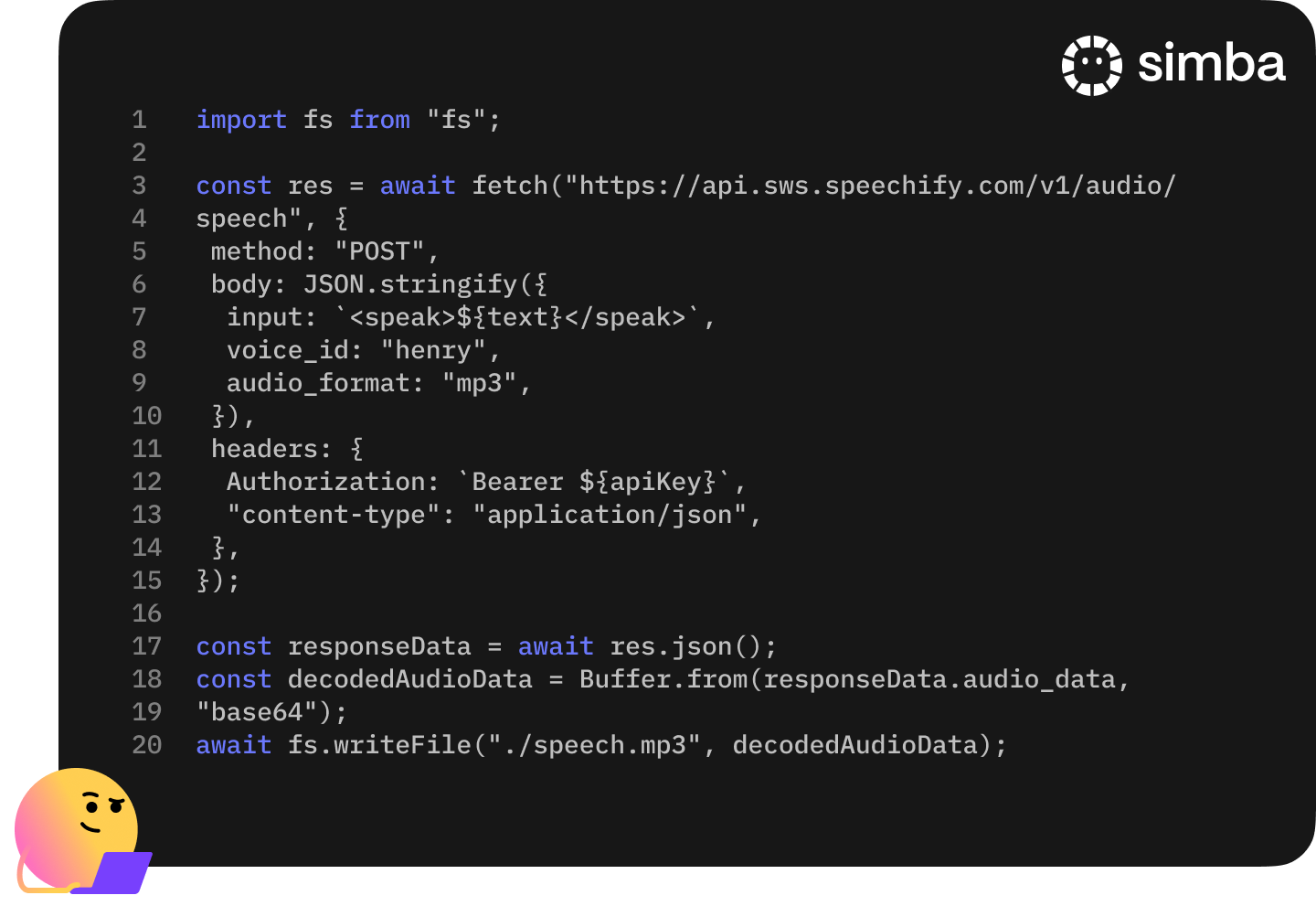
Introducing Our Text To Speech API
We're sharing an AI Voice API that delivers Speechify's most natural and beloved AI voices directly with developers
Get Educated on AI Video Dubbing
Whether you are just beginning or a pro, get the best articles on dubbing
FAQ
AI dubbing is the process of using artificial intelligence to generate voice overs for videos in different languages, rather than using traditional human voice actors.
Speechify Dubbing is the best option. With Speechify, anyone can do voice dubbing online for free. Simply choose an AI voice, language, and hear your script read aloud in a new language.
Traditional voice dubbing, or content for translation, involves voice actors who manually replace the original voice tracks with new ones in a different language. With AI dubbing, such as Speechify Studio, the process is automated. The AI transcribes the original dialogue, translates it into a different language, and uses text to speech algorithms to create the new voice track.
An example of dubbing is taking an English-language movie and replacing the English dialogue with Hindi, using AI voices. This involves transcribing the original English dialogue, translating it into Hindi, and then using text to speech technology to generate the new Hindi dialogue, which is read aloud in lifelike AI voices.
VO, or voice over, refers to the process of adding a voice narrative to video content, typically to provide commentary or explain what is happening. Dubbing, on the other hand, involves replacing the original dialogue in a video with dialogue in a different language. Both processes can be enhanced using AI technology, such as Speechify Studio, for a more efficient and cost-effective localization strategy.
To dub in AI, you will need to use an AI dubbing service such as Speechify Studio. These services usually require you to upload your video content. The AI then transcribes the original dialogue, translates it into the desired language, and uses text to speech technology to read aloud the scripts and create the new voice track.
AI dubbing offers several benefits. It improves the accessibility of video content, making it available to a wider audience that speaks different languages. It also provides a cost-effective and time-saving solution compared to traditional dubbing methods that involve coordination with voice actors. High-quality AI dubbing can enhance the viewing experience by providing real-time dubbed content without the need for subtitles, and it’s particularly beneficial for content creators, e-learning platforms, and social media.
Dubbing is a process in filmmaking and television production in which the original vocal tracks recorded during filming are replaced with voices recorded in a different language.
In movies, dubbing refers to the practice of replacing the original dialogue with translated dialogue in a different language. This process allows the movie to be understood and appreciated by audiences who do not speak the language of the original dialogue. The dubbed voices are typically synchronized with the actors’ lip movements to maintain continuity and believability.
Dubbing in TV shows involves replacing the original dialogue with translated dialogue in another language. This enables the show to reach a wider audience who speak different languages. The process involves matching the dubbed voices with the actors’ mouth movements and expressions to ensure a seamless viewing experience.