Studio AI Nombor 1
Kedai Suara & Video Serba Lengkap
Dipaparkan Dalam
Speechify Studio ialah suite AI menyeluruh pertama untuk pencipta
Daripada kedai sehenti ke pasukan kreatif, semua jadi lebih mudah.

Penduaan Suara
Cipta klon suara manusia berkualiti tinggi dengan AI dalam beberapa saat. Tiada pemasangan. Terus dari pelayar anda.
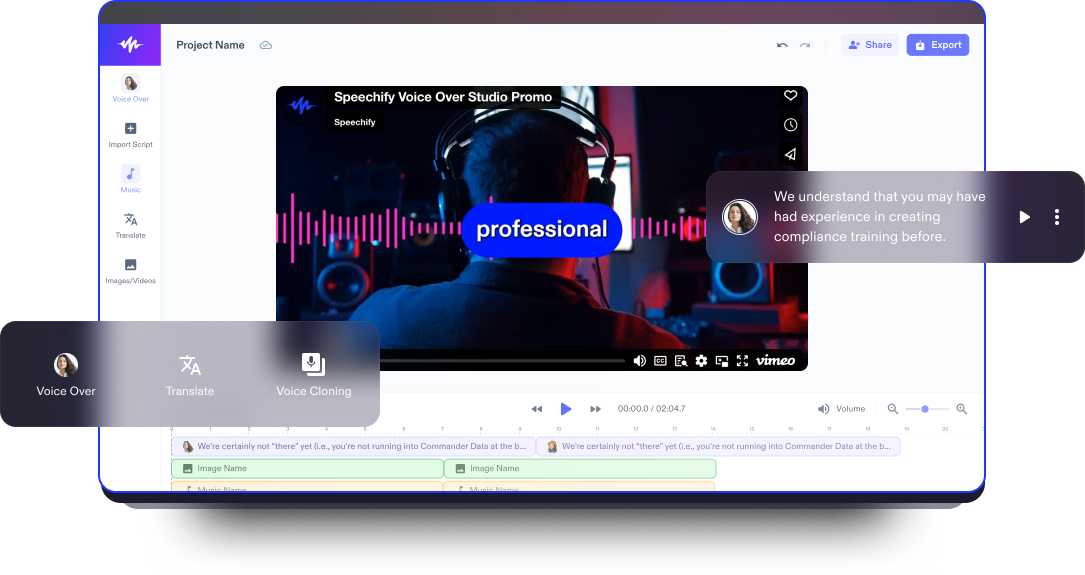
Suara Latar
Cipta suara latar berkualiti setanding suara manusia secara masa nyata dengan AI. Narrasikan teks, video, penerangan – apa sahaja – dalam apa jua gaya.

Studio Video AI
Cipta dan sunting video dari kosong dengan alat AI kami. Studio penyuntingan & penciptaan video semua dalam satu.

Alih Suara AI
Tukar video anda ke mana-mana bahasa dengan satu klik. Padankan suara, intonasi dan kelajuan penutur.
Cuba sendiri pengalamannya
Ini hanya sebahagian perkara yang anda boleh buat di Speechify Studio.
Bina suara latar, tambah imej stok tanpa royalti, audio, video, klon suara anda, untuk projek audio video yang lengkap.
Tanpa keluk pembelajaran dan semua boleh diakses terus di pelayar, pencipta boleh realisasikan segala idea kreatif mereka tanpa batasan.

Banyak pilihan suara lelaki dan wanita dengan pelbagai loghat
Setiap projek boleh jadi unik. Pilih ratusan pelakon suara AI & loghat, laraskan ikut cita rasa anda.






Speechify Studio untuk pasukan pelbagai saiz
Speechify Studio memudahkan kerja pasukan kreatif daripada seorang individu hinggalah ke syarikat besar.
Urus pasukan, kongsi aset, bekerjasama, dan lancarkan kempen lebih pantas berbanding sebelum ini.
Terokai Lagi
API Teks ke Suara Speechify
Kami teruja memperkenalkan binaan API teks ke suara yang membawa suara AI Speechify paling semula jadi kepada pembangun di seluruh dunia.